Using Natural Language Processing for the analysis of global supply chains

We have been working with the Department for Business and Trade (DBT) to show how data science techniques can enable and enhance the analysis of global supply chains.
The coronavirus (COVID-19) pandemic highlighted issues related to global supply chain risks, such as shortages in microchips and personal protective equipment. Additionally, other events can result in supply chain shocks, for instance, the Suez Canal crisis and the closure of major copper mines in the Democratic Republic of Congo and Zambia. It is therefore important to study global supply chains, to detect and mitigate related risks.
In this project, we explored whether cutting-edge data science techniques, such as natural language processing (NLP) and transformer-based deep learning models, could enable us to construct supply chain networks from unstructured text. We applied these techniques to sentences from Reuters news, similar to the one used by Wichmann et al. 2022, kindly provided by researchers from the Supply Chain AI Lab of the University of Cambridge and a selection of sentences from the BBC Monitoring database. Additionally, we wanted to learn more about the opportunities and challenges associated with using such models, since they are potentially applicable to a wide range of use-cases. Our aim was to detect buyer-supplier relationships implied in sentences of news articles. This work can help with the validation of existing supply chain networks and the enrichment of the networks with previously unseen relationships.
The project is affiliated with the Global Supply Chains Intelligence Pilot (GSCIP), run by DBT, which aims to explore the value of combining several government and external datasets, along with big data analytics, to map global supply chains. Several UK government organisations participate in the pilot, including Cabinet Office, Office for National Statistics, HM Revenue and Customs, Department for Business, Energy & Industrial Strategy and UK Export Finance.
Our initial results indicate that, by applying the above-mentioned techniques, we can detect buyer-supplier relationships between enterprises in sentences from news articles with good accuracy, when these are relevant to themes or topics that our models encountered during training. Moreover, our model can recognise such relationships in unseen topics.
Data science techniques
Supply chains can be represented as knowledge graphs, for example Kosasih et al. A knowledge graph is a diagram of interlinked descriptions of these entities can include products, countries of origin, firms or transport modes and other characteristics
To build the knowledge graph, it is necessary to determine the entities and the relations between them. In our analysis, these entities are enterprises, and our goal is to determine whether there exist buyer-supplier relationships between them. Potential pathways for future work include expansion of our analysis to other types of entities, such as products and countries of origin.
During our analysis, we developed a sample pipeline, which can be used to build knowledge graphs from collections of free text. This pipeline consists of the following steps:
- sentence segmentation
- entities extraction
- entities filtering
- relations extraction
- construction of knowledge graphs
- network analysis
Each of these steps can be completed with a variety of data science algorithms, although for the purpose of this work we haven’t considered network analysis and entity filtering.
Sentence segmentation
This is a preliminary step that splits the text document into sentences and is necessary to extract entities with accuracy in the following step. It can be performed with sentence tokeniser tools, such as PunktSentenceTokenizer, implemented in the widely used NLTK package.
Entity extraction
During this step, entities of interest are extracted from sentences. This is a classification problem, which assigns words (typically, nouns) in a sentence to a number of predefined categories. These could represent names, companies, products or even numbers, for instance transaction values or revenues.
This step can be performed with techniques from the families of sequence analysis (Bayesian models are commonly used, for example, hidden Markov models and conditional random fields).
Deep learning (for instance, convolutional neural networks – an important step here is to convert words to word embeddings, which allows words with similar meanings to have a similar representation).
And rule-based approaches (Brill’s speech tagger is widely used here). In our case study, the entities of interest are enterprise names.
Entity filtering
It is expected that in collections of articles with diverse content, for instance, news articles, some extracted entities will not be relevant to global supply chains. To filter out irrelevant entities, one approach could be to discover the abstract topics that occur in the collection of articles (with topic-modelling techniques, such as latent Dirichlet allocation, latent semantic analysis, probabilistic latent semantic analysis) and then remove all terms related to irrelevant topics.
Relation extraction
Here we determine the relations between the detected entities. This can be achieved with three broad approaches, which are syntactic patterns (for example, Hearst patterns), supervised approaches (e.g., RNNs, LSTMs, transformers, these require a lot of training data) and weak supervision approaches (for instance, the algorithms by Onishi et al. and Riedel et al.).
In our study, we use transformers for relation extraction. Transformers are attention-based models and improve on previous algorithms used for relation extraction. Their main advantages over Recurrent neural networks (RNNs), Long short-term memory networks (LSTMs), Convolutional neural networks (CNNs) are are that they do not suffer from long dependency issues such as long sentences and can be trained efficiently.
Construction of knowledge graphs
Having detected the entities and their relations, the knowledge graph can be constructed with network visualisation tools (for example, the networkx library). The nodes of the network will be the entities and the edges between the nodes will be the relations between the nodes.
Network analysis
Once the knowledge graph is constructed, it can be further analysed with network analysis techniques to solve problems relevant to supply chains such as identifying critical products, critical routes, and the strength of relations between entities.
In the applications that follow, we apply the following steps: sentence segmentation, entities extraction, relations extraction and construction of knowledge graphs and the remaining steps may be explored in future work.
Application to Reuters Data
We evaluated our pipeline’s performance using a database of sentences from Reuters news. This is similar to the one used by Wichmann et al. 2022, and was provided by researchers from the Supply Chain AI Lab of the University of Cambridge.”
The data comprised 7,274 aerospace and automotive news article sentences, pre-labelled with company names and relationships between them.
Approximately 10% of relationships were directed supplier-customer relationships, 20% subsidiary or other specified relations, and the remaining 70% “no relation”. Table 1 shows a full list of relation annotations contained in the data.
Table 1: Annotations of entities’ relations
| Label | Relation |
| A supplies B | The first-named organisation supplies the second-named |
| B supplies A | The second-named organisation supplies the first-named |
| Subsidiary | Ownership relations; part-of relations |
| Other Relation | Non-directed buyer-supplier relations; ambiguous relations; partnerships and collaborations |
| No Relation | No relevant relation detected |
Here is an example sentence from the database, with its annotations:

Sentences were also provided in an alternative form, in which organisational entities were replaced with a mask, for example:

We used a supervised learning approach to detect buyer-supplier relations in the data. That is, we used part of the database to build a model that detects relationships and then applied the model to the remaining part of the data to automatically extract the relations between entities in the text. Specifically, we used 70% of the data for training, 15% for validation and 15% for testing.
We detected relationships between enterprises in the data with transformer neural networks within the spaCy NLP framework tied to pre-trained transformer models from the huggingface library. The implementation for the relation extraction task was based on spaCy’s relationship extraction template (rel_component), which fine tunes transformer models using training data.
Relationships between entities were learnt either using all the words in a sentence (unmasked data), or only the non-entity words in a sentence (masked data). The use of organisational names might give clues as to the relations between entities, through the words themselves, such as “ABC Airlines”, through the prevalence of the names in the dataset, or through background knowledge about the organisations, such as Boeing. On the other hand, excluding these names might help generalisation if the learned model is applied in a different domain.
Challenges in the relation extraction task include the varied or ambiguous ways that supplier relations can be represented in text. For example, who is supplying whom in this sentence:
“GKN Aerospace has signed a GBP multi-million, long term agreement (LTA) with Kawasaki Heavy Industries (KHI) to supply titanium rotating parts for the PW1100G-JM and PW1400G-JM, Geared Turbofan (GTF) engines.”
This difficulty is partly evidenced by the variation in relation labelling between different labellers in the original dataset.
Here, we present results for the default transformer model in the spaCy template, that is, RoBERTa (base) (“A Robustly Optimized BERT Pretraining Approach”), a refinement of BERT (Bidirectional Encoder Representation from Transformers). Table 2 shows full results for the base model, Roberta-base masked. This gives an “A supplies B” relation identification with precision of 0.961 and recall 0.85 and “B supplies A” identification with precision of 0.95 and recall of 0.83. It also includes results for subsidiary and “other” types of relation, though at a somewhat lower performance.
Table 2: Roberta base masked data (‘base’ results highlighted)
| Label | Precision | Recall | F1-Score |
| A supplies B | 0.96 | 0.85 | 0.90 |
| B supplies A | 0.95 | 0.83 | 0.89 |
| No Relation | 0.92 | 0.94 | 0.93 |
| Subsidiary | 0.61 | 0.65 | 0.63 |
| Other relation | 0.82 | 0.90 | 0.86 |
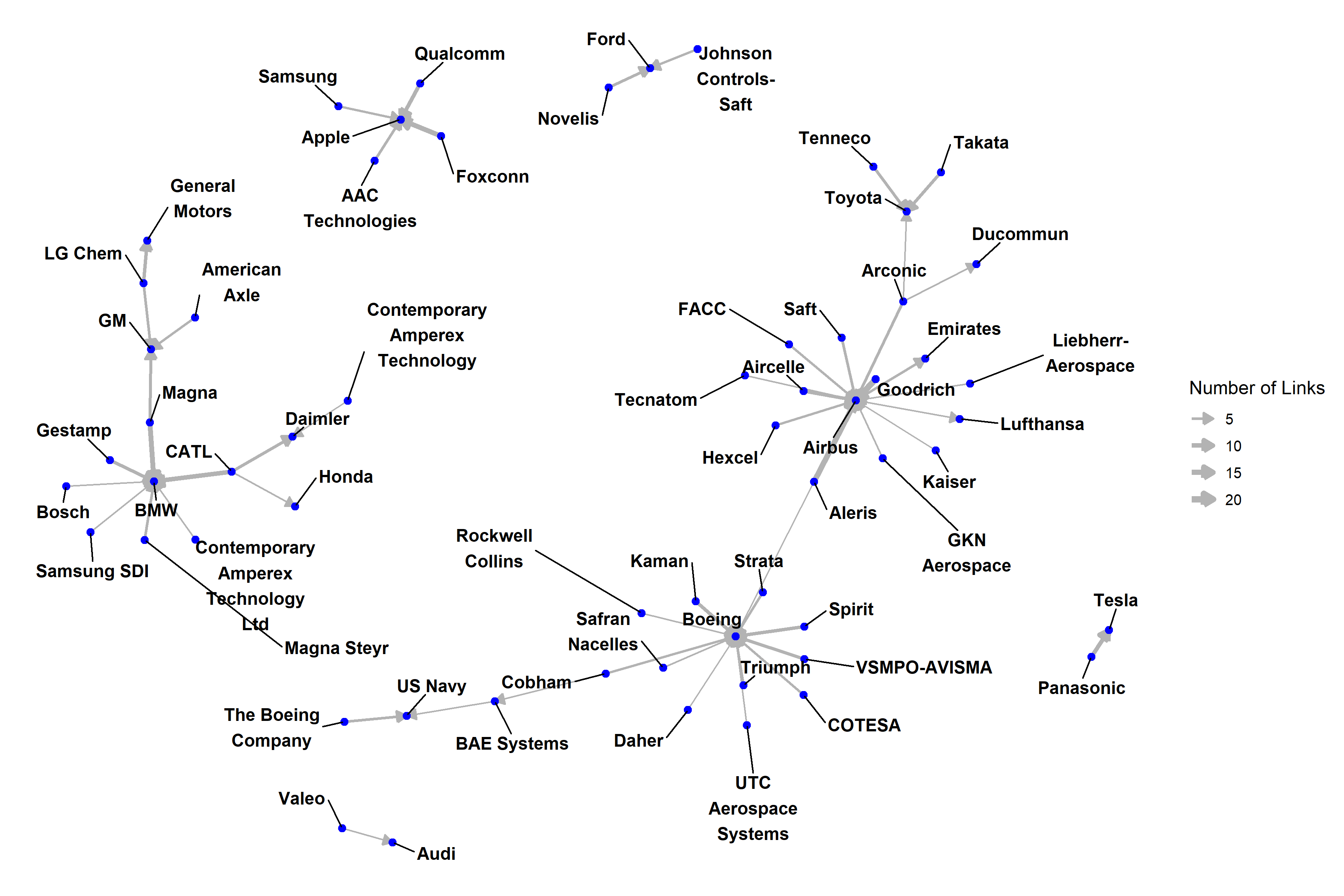
We used the ggnetwork package in R to visualise the customer-supplier relations in the above data, for companies having at least four relations, as shown in Figure 1. Airbus and Boeing are the largest hubs, as well as car manufacturers BMW, GM, and Toyota, and there is separate sub-network for Apple.
Figure 1: Supply chain visualisation
Application to BBC monitoring data
We also applied our model to a selection of sentences from the BBC Monitoring database, which is a collection of insights and reports from broadcast, press and social media sources from over 150 countries and 100 languages. It was challenging to build a database for our experiments because potential buyer-supplier relationships were scarce and difficult to identify within a big database of the size of BBC Monitoring.
Therefore, we selected a few sentences by ensuring that each of them had at least two named entities and contained a phrase from a predefined list of key phrases that could imply buyer-supplier relationships. Our final database consisted of 897 samples. Note that for this experiment we used the model we had previously trained on Reuters data for our previous application. The BBC monitoring database and the selection of sentences we used for testing were completely unseen by our model.
Ground truth for each sentence in the sample was provided by human annotators, who assigned a label to each pair of named entities in each sentence of the BBC monitoring sample. Each of these labels indicated the type of the relationship between the pair of named entities. The labels we used are shown in Table 1.
The type of relation between two named entities in a sentence is often ambiguous. Therefore, each relation in the sample was annotated by three independent annotators and its final ground truth label was assigned by majority voting.
Overall, our model was capable of correctly identifying the relationships between named entities implied in the sentences in 90.65% of the examples of our database, which indicated its capability of achieving high performance even for completely unseen data. In terms of identification of named entities, our model was able to identify them reliably in all cases.
Tables 3a and 3b show initial results from the application of our model to the sample from the BBC monitoring database. The model’s output is shown in table 3a and table 3b has some additional information relating to the analysis of the output and the sentence annotation process.
As mentioned previously, the task of determining the type of relationship between two entities can be challenging even to a human. We can see that in the examples 7 and 10 of Tables 3a and 3b, the model did not find the type of the relationship specified by the majority of the human annotators but one of the human annotators specified the same relationship type as our model.
It is noteworthy that the model can detect buyer-supplier relationships correctly from a multitude of completely different expressions, which can be more complex than the standard expression “A supplies B”. In sentences 1, 2 and 8, the expressions “among its clients are”, “is implemented jointly with” and “produces super pure materials used by” were used, respectively, and the implied relationships were correctly detected by the model.
Table 3a: Initial results from the application of our model to the sample from the BBC monitoring database.
| Sentence | From | To | Relation identified | |
| 1 | Oracle is a developer of data storage systems, among its clients are the Ministry of Finance, the Central Bank, Russian Post, Sberbank, Rostelecom, Rosatom, etc. | Oracle | the Central Bank | A supplies B |
| 2 | The Vodafone Ukraine project is being implemented jointly with DTEK and Ericsson. | Vodafone | Ericsson | Other Relation |
| 3 | Already in the financial statements for 2020, Ericsson introduced a warning that the Swedish blacklisting of Huawei may have a negative impact” on “Ericsson’s financial interests. | Ericsson | Huawei | No Relation |
| 4 | Atameken Business Channel carries business and financial news in cooperation with Bloomberg, Thomson Reuters, the Kazakh Stock Exchange and Russia’s Interfax news agency. | Atameken Business Channel | Bloomberg | Other Relation |
| 5 | By BBC Monitoring Russian state energy giant Gazprom says it will stop supplies of natural gas to the Dutch trader GasTerra due to its reported failure to pay for fuel it has already supplied. | Gazprom | GasTerra | B supplies A |
| 6 | Interaction between the Finance Ministry, the National Bank and the Agency for Regulation and Development of the Financial Market should be strengthened to implement a plan of action for including government securities in international indexes,” Tokayev said. | the Finance Ministry | the Agency for Regulation and Development of the Financial Market | No Relation |
| 7 | During the drill, Sber simulated turning off IT infrastructure supported by Microsoft, Nvidia, VMware, SAP, Oracle and Intel, the paper said on 1 February. | Sber | Intel | No Relation |
| 8 | Kupol General Director Fanil Ziyatdinov said that Kupol also produces super pure materials used by leading companies such as Intel, IBM, Samsung and Apple in smartphones. | Kupol | Apple | A supplies B |
| 9 | KPN wanted to replace Huawei in its core network with equipment from Sweden’s Ericsson anyway, and Vodafone barely used network components from China. | KPN | Vodafone | B supplies A |
| 10 | Vodafone Spain opts for Ericsson instead of Huawei to test 5G network Vodafone Spain has chosen the Swedish technology company, Ericsson, for a test of its first 5G standalone core network, the Spanish business newspaper Expansion reported on 24 June. | Vodafone | Ericsson | No Relation |
| Annotator 1 | Annotator 2 | Annotator 3 | Relation (Majority) | Correctly identified? | |
| 1 | A supplies B | A supplies B | A supplies B | A supplies B | Yes |
| 2 | Other Relation | B supplies A | Other Relation | Other Relation | Yes |
| 3 | No Relation | No Relation | No Relation | No Relation | Yes |
| 4 | Other Relation | Other Relation | Other Relation | Other Relation | Yes |
| 5 | A supplies B | A supplies B | A supplies B | A supplies B | No |
| 6 | No Relation | Other Relation | No Relation | No Relation | Yes |
| 7 | No Relation | B supplies A | B supplies A | B supplies A | No |
| 8 | A supplies B | A supplies B | A supplies B | A supplies B | Yes |
| 9 | No Relation | No Relation | No Relation | No Relation | No |
| 10 | No Relation | B supplies A | B supplies A | B supplies A | No |
Conclusion
We have presented initial results for automatic extraction of buyer-supplier relationships from news articles using NLP techniques, with the aim to extract supply chain information. We showed that our model performed well for sentences from a domain relevant to the data used when training the model. Furthermore, the model is capable of correctly identifying relationships between entities in sentences extracted from databases unseen to the model.
Naturally, we also discovered several challenges in our work. These include access to sources of text that describe rich, deep supply chains, constructing a high-quality labelled dataset, model explainability, technology requirements (including hardware) for larger-scale model training, model serving in production and keeping the derived supply chain network up to date.
In future work, possible extensions could be to apply our method to domains and text types outside of the training data and to include other types of entities in our analysis, such as products and countries of origin.