ClassifAI – Exploring the use of Large Language Models (LLMs) to assign free text to commonly used classifications

Overview
Assigning free text to a set of categories is a common activity for National Statistical Institutes (NSIs), for example industry or occupational classifications. Currently a combination of manual, rules-based, and machine learning techniques are employed for this purpose. We are developing a new tool, “ClassifAI”, which is an experimental text classification pipeline using Retrieval Augmented Generation (RAG) that aims to improve on existing approaches with regards to flexibility and accuracy.
Today, we are releasing the code base for a proof-of-concept pipeline that tests this new approach on GitHub. The code should not be used in a production setting without further assessment and validation and is being made available for research purposes only. The repo contains short tutorials and guidance for how to apply this approach for any custom classification, and any number of input text fields. The pipeline can be deployed locally using Streamlit for interactive evaluation.
We have piloted the approach by classifying deidentified free text from labour market surveys to the Standard Industrial Classification (SIC). It is straightforward to extend the same approach to other classification systems, such as Standard Occupational Classification (SOC) or Classification of Individual Consumption According to Purpose (COICOP). Initial results have been promising, demonstrating a marginal improvement in agreement with manual human classification compared with existing approaches, at different levels of classification hierarchies.
However, there are practical challenges to implementation, and further work that needs to be undertaken before considering use in the production of official statistics.
We hope this work will inform and support collaboration with others who are looking at similar approaches and welcome feedback on our approach. As this is an exploratory proof of concept, we expect users to discover bugs and vulnerabilities, and we welcome feedback on all aspects of this repository.
Background
Data classification is fundamental for organisations involved in producing economic and social statistics. For instance, a key process for compiling UK labour market statistics is assigning labour market survey free text responses to SIC and Standard Occupational Classification (SOC) and codes. The same process is also needed for a range of other statistics, including household expenditure and trade statistics.
For free text classification, ONS use a range of approaches, including knowledge base lookups, traditional machine learning approaches, and clerical review. These approaches can be very effective, however, there is value in examining the potential for new technology especially LLMs, as they are conceptually well-suited to classifying free text and may outperform traditional machine learning approaches (such as logistic regression) by being able to better distinguish spelling mistakes, sentiment, and other nuances.
We have set out to build and test an experimental, RAG based text classification pipeline, that can conceptually be used for any custom classification, is flexible to handling a variety of input text fields, is secure in terms of how it handles data, and is scalable in being able to handle large requests with low latency. We then tested whether this approach delivers an improvement in accuracy as well as flexibility, in terms of the ability to classify text to a specified level of granularity and accuracy against existing approaches.
Method
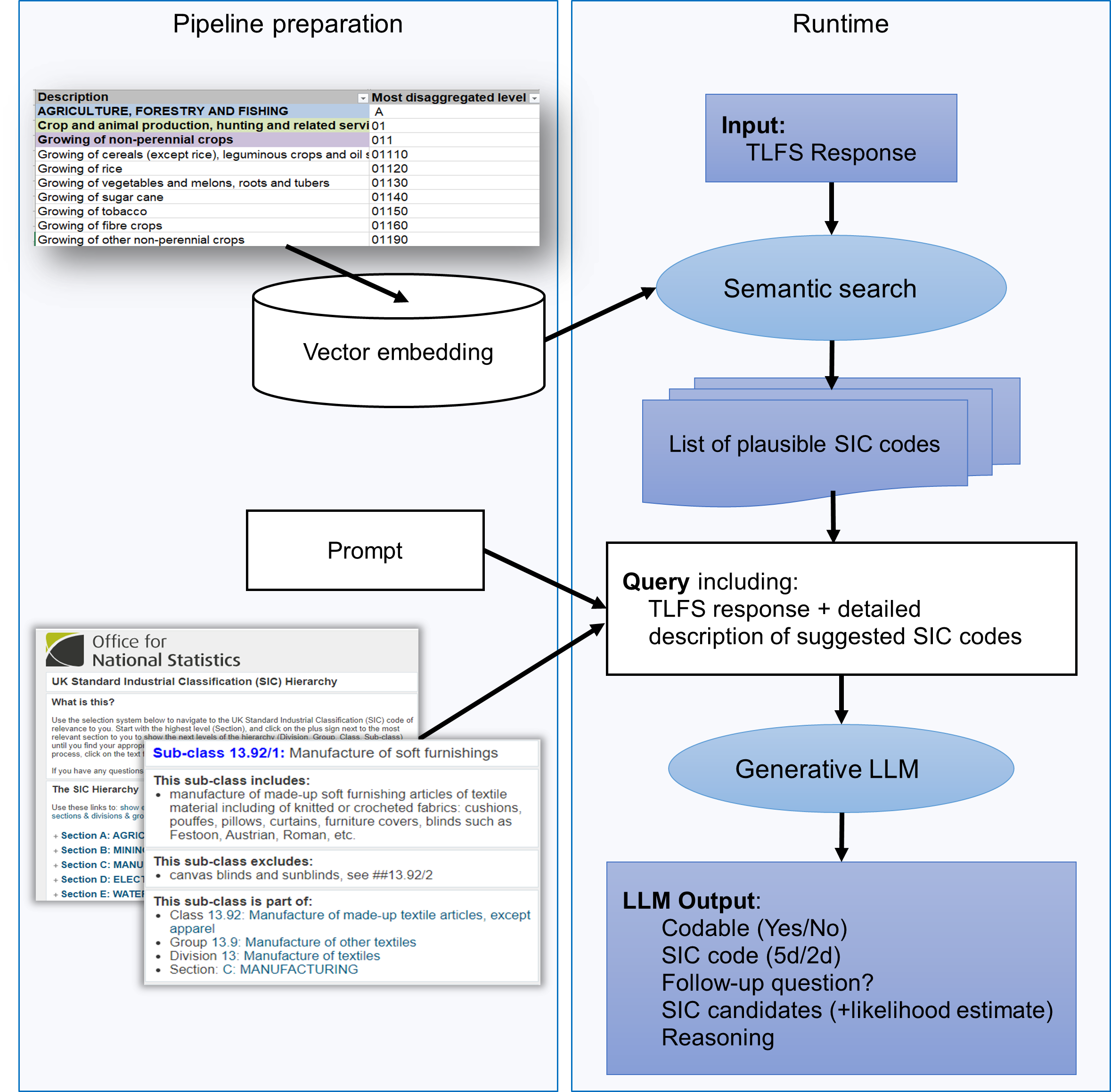
The approach we tested was based on the common RAG design (Figure 1), involving two main steps. First, we conducted a semantic search for relevant SIC index candidates based on the survey free text. This was achieved by embedding a knowledge base, consisting of the SIC classification descriptions, along with a list of activities that cover each corresponding SIC code, using the MiniLM transformer language model (although the pipeline is flexible to using different models to achieve this).
The same model was used to convert the survey response text needed to be classified into a form that could be compared with the embeddings of the activities in the knowledge base, resulting in a shortlist of candidate SIC codes.
We then queried a general-purpose pretrained model (Gemini-Pro) to evaluate which SIC code candidates best fit the response. The LLM was presented with the response and a list of the SIC descriptions and was tasked with determining the most appropriate code from the candidates
The model was programmed to return an “uncodable” status and provide a suggested follow-up question if it is difficult to allocate the text to a single code. The ability to return output in this format is potentially valuable for onward data processing, as it represents a clear way to flag when the source data do not allow a classification decision to be made and provides a feedback loop as to why.
Both steps rely on pretrained transformer-based models, that excel at identifying the semantic meaning of words and handling unseen responses, which could also potentially lead to improvements in the accuracy of categorising emerging jobs and industries. The code base is flexible, allowing model changes for both the semantic search and LLM based selection, to benefit from future improvements.
The output of the process includes fields for easy analysis:
- Codable (Yes/No): Indicates whether the survey response could be assigned a SIC code.
- SIC Code: Contains the SIC code determined to be the best fit.
- Follow up Question: Specifies a suitable follow up question to clarify the response if an appropriate SIC code cannot be determined.
- SIC Candidates: Lists potential SIC codes considered, each with likelihood estimates.
- Reasoning: Provides an explanation of why the LLM selected a particular SIC code or decided the correct code could not be determined.
Both the reasoning and follow up question fields could be helpful for clerical coders and questionnaire designers to understand any persistent issues in the questionnaire wording and help refine processes.
Figure 1: Visualisation of system design
Data and results
We used deidentified labour market survey data to evaluate the effectiveness of the LLM based approach, focusing on open text responses for job title, job description, and industry description. These responses come from questions such as:
What is your job title in your main job or business?
What do you mainly do in that job or business?
At your main job, what does the firm or organization mainly make or do?
The dataset was formed from multiple clerical coding exercises covering thousands of responses over the period October 2023 to March 2024 inclusive. Performance was evaluated by checking the levels of agreement between clerical coders, a logistic regression benchmark, and the LLM based approach.
For data that could be clerically coded, we found a marginal improvement in accuracy, for the 2- and 5-digit SIC levels respectively. We found that the LLM-based classifier was able better interpret technical jargon or very specific pieces of information by drawing on wider context, which may mean it is well suited to handling difficult cases where traditional machine learning approaches give a low confidence score against the prediction.
Open experimental toolkit
We have made the code repository for this proof-of-concept publicly available. It contains an experimental implementation of a pipeline that could be used for a general-purpose classification tool, but further assessment and validation would be needed before it could be used in a production setting.
The accompanying documentation provides information about the data sources used in the example classification indexes, as well as step-by-step instructions for installing and integrating the package pipeline into your own projects or running it within a local Streamlit application.
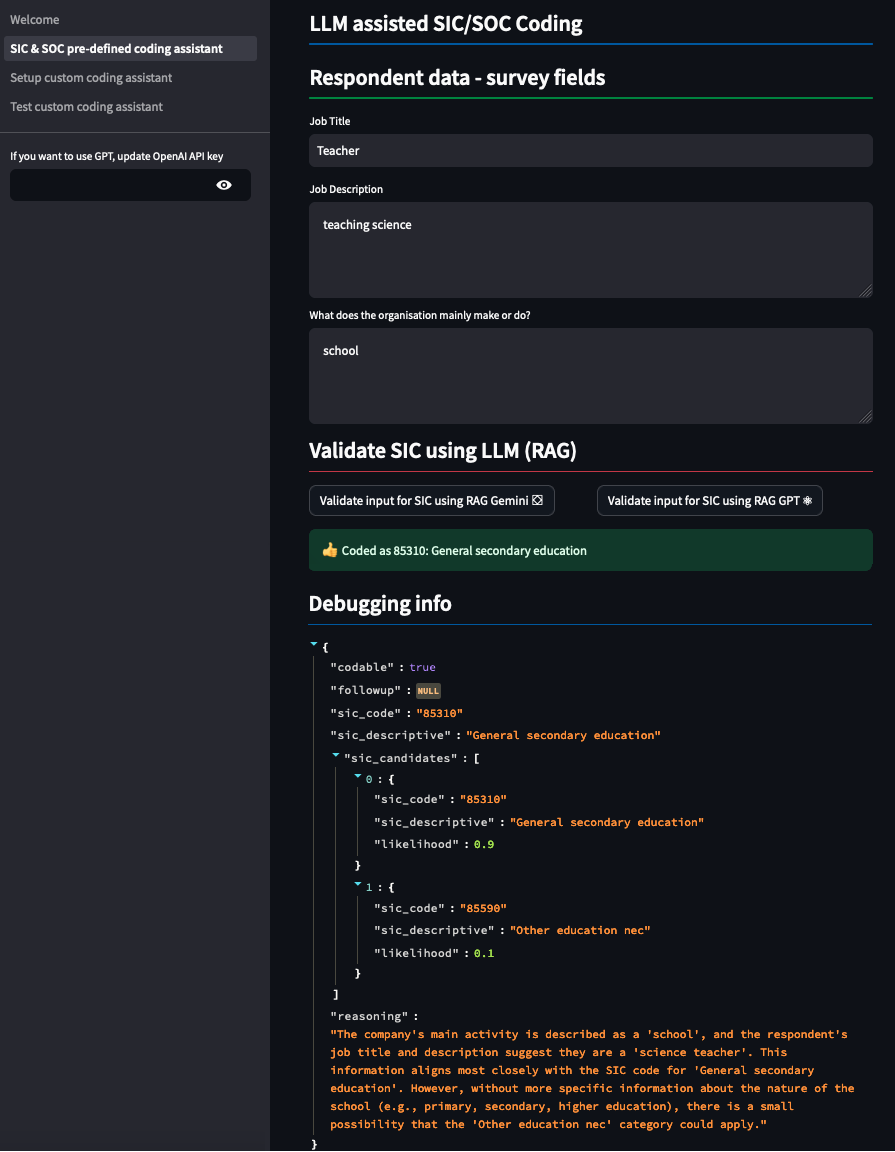
A simplified example of the application’s user interface is shown in Figure 2, including output for a hypothetical set of information.
Figure 2: Example Streamlit interface for SIC and SOC classification
As this is an exploratory proof-of-concept, we expect users to discover bugs and vulnerabilities, and we welcome feedback on all aspects of repository. The code is being made publicly available solely for research purposes, and we are actively working to ensure the tool meets rigorous tests of data security and ethics. Users are welcome to submit issues on GitHub. We also welcome anyone interested in putting these ideas to use, to contact us at the Data Science Campus.
Next Steps
This promising proof-of-concept indicates there are likely to be benefits in exploring LLM based text classification by NSIs. The tool is still very much in an experimental phase, having been developed in a short space of time, and method refinements could improve performance further, though it is difficult to quantify to what extent this might be. Fine-tuning the models at the embedding search stage, which was out of scope of the initial test but is being actively explored, is likely to lead to performance improvements.
We have shown that it is possible to add an LLM based approach to a toolkit of different classification approaches (For example, rules-based matching, clerical coding), but significant further work is required to implement an approach into production. This includes assurance that the approach meets the highest tests of data privacy and security. Efforts are ongoing to assure methods, understand strengths and weaknesses, optimize system design, and assess potential bias.
If you are interested in this work or would like to collaborate with us on a similar project, get in touch with us via email. For regular updates on our work, follow us on X and sign up to our newsletter.