Developing a Privacy Preserving Record Linkage toolkit

The PPRL toolkit demonstrates a layered approach to security, which has been called the ‘Swiss cheese’ model
Overview
The Office for National Statistics (ONS) – along with other public sector institutions – rely on the ability to link datasets to produce new analysis and improve statistics for decision-making. As Sir Ian Diamond, the National Statistician, says “We find ourselves living in a society which is rich with data and the opportunities that comes with this. Yet, when disconnected, this data is limited in its usefulness. … Being able to link data will be vital for enhancing our understanding of society, driving policy change for greater public good and minimising respondent burden.”
Data linking often needs to happen across organisational and national boundaries, which can create data privacy risks as personal information such as names, addresses, and dates of birth are often needed to do this accurately. The ONS takes very seriously its responsibility to link datasets securely, ethically and robustly, and is taking a leading role in exploring how new technology can help us achieve this.
Today, we are releasing an experimental Privacy Preserving Record Linkage toolkit, which we hope will help organisations with this challenge. It combines secure cloud computing with innovative data linkage methods to achieve accurate linkage capabilities without sharing personal information. It currently consists of an open-source codebase, and scripts to set up a secure cloud environment and user interface to conduct the linking, along with some tutorials that demonstrate how it can be used.
It is available on GitHub for anyone to test and provide feedback on the tool, although it is important to stress that this is currently a proof of concept. We advise organisations to adapt and independently assure any implementations of the methods in this toolkit.
This project grew out of and has benefitted greatly from collaborations with colleagues at NHS England.
We are sharing this toolkit as a call to action for the wider community to collaborate, to develop privacy preserving record linkage methods and unlock their benefits.
Initial results and performance
Using embedding-based data linkage in an “eyes-off” setting, we have achieved impressive results. The Freely Extensible Biomedical Record Linkage (FEBRL) package comes with four datasets that have been used in other packages (recordlinkage and Splink) to demonstrate and evaluate matching. FEBRL 4 consists of two datasets of 5,000 records each, with a match for each record and no duplicates.
- out of the box, the PPRL toolkit, using the Bloom filter method, matched 4963 records (99.3% recall), no false positives (100% precision)
- a published Splink demo matched 4960 records (99.2% recall), no false positives (100% precision)
The linkage toolkit includes features that make the process of matching more automatic, by providing reasonable defaults for data processing and matching thresholds. These features enable matching to be conducted in a secure enclave or in another “eyes-off” setting.
Technical solution
The Python package implements Hash embeddings (Miranda et al., 2022), which are an extension of the Bloom filter linkage method (Schnell et al., 2009). Personal data for each respondent – such as names, dates of birth and addresses – is transformed or “hashed” into a long vector of ones and zeroes. This binary vector, the Bloom filter, encodes the information in the raw data, but it is very difficult to use the code to find out the original data.
Hash embeddings take this idea one step further: by using a large corpus of data that has already been matched, we can pretrain a model that learns the associations between different features in the data, to improve the matching performance of the method. For example, a Bloom filter might be able to match the names “Catharine” and “Katharine”, but then might struggle with variants such as “Kitty”.
An embedding can be trained to learn these associations between variants of the same name. The same principle applies to other data types such as business names, dates of birth, or addresses. Our Python package can use both untrained Bloom filters and Hash embeddings, depending on requirements and the availability of training data.
Although embedding methods effectively obfuscate data, they are still vulnerable to certain kinds of attacks. For example, given enough computing power and a large database of identifiers, a malicious third party could statistically analyse the embeddings to find out who is likely to be in the dataset.
The technical solution we have proposed for this is to set up a third-party secure cloud “enclave”, where the linking is undertaken. An enclave is a computer where computations can be done in the cloud. It is just like a normal cloud server, with the difference that data is encrypted, not only when it is being stored or transmitted, but also when the server is holding the data in memory.
The two organisations encrypt their respective datasets, using keys obtained from their own cloud-based key management services, and send them to the enclave. The enclave then sends a special message, called an attestation, to each organisation’s key provider – the attestation proves that the server is running in a secure enclave, and that data cannot be seen by employees of the cloud provider, or anyone else.
When it receives a valid attestation, the key management service allows the enclave to use the key to unlock the data. However, it remains encrypted using the enclave’s own in-memory encryption throughout the matching process. When the matching is done, the enclave encrypts the matching result, and sends it back to both organisations.
Figure 1: Example diagram for the PPRL server architecture
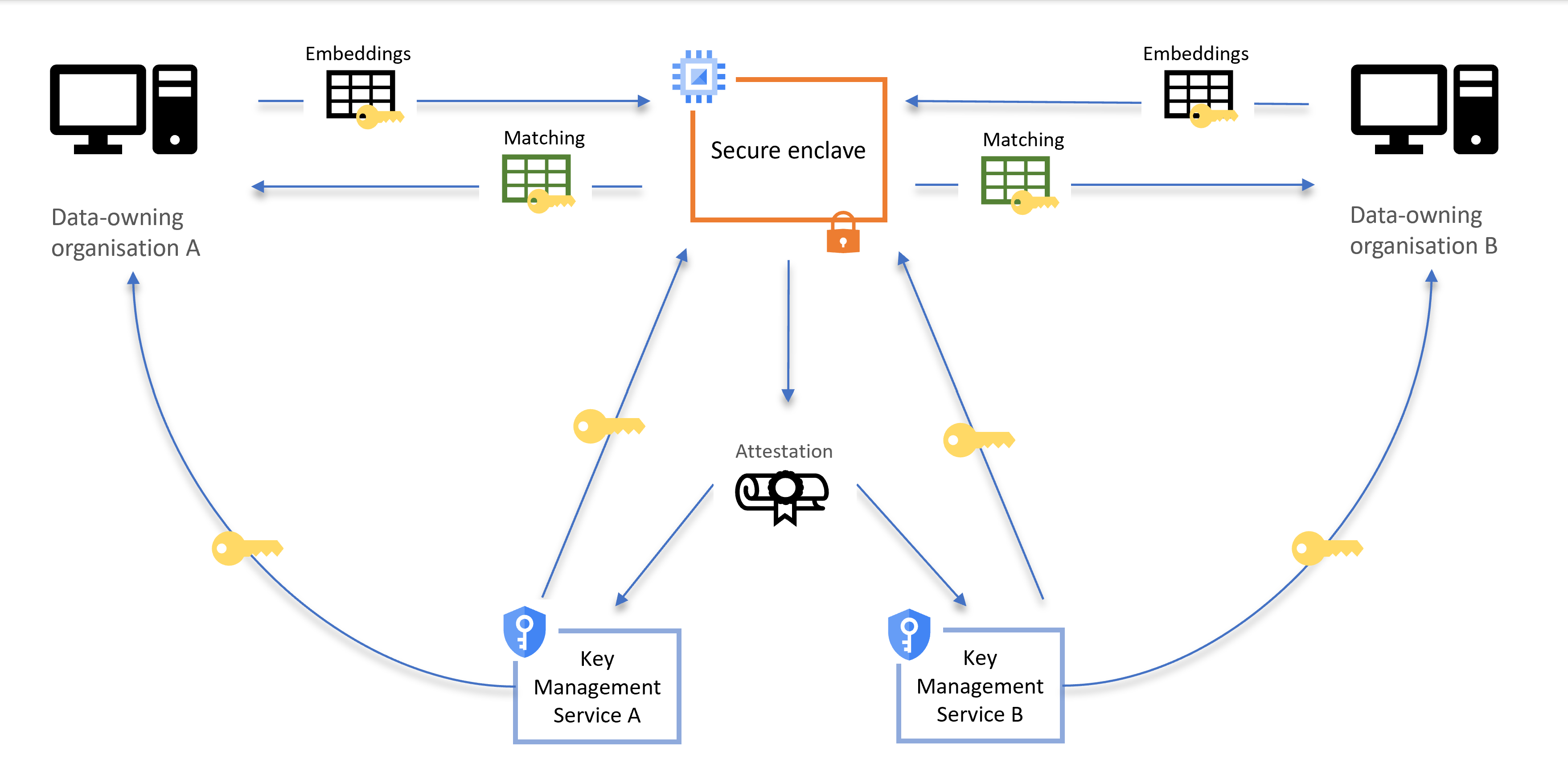
This approach to overlapping security has been called the “Swiss cheese” model: imagine thin layers of Emmental, stacked so that the holes in one layer are covered by the next layer. The approach is designed to take advantage of several layers of security. It uses a combination of algorithms, encryption, and secure cloud technologies that reinforce each other and ensure that sensitive information cannot be recovered by those who should not see it.
Toolkit
Our design focuses on minimising the amount of infrastructure configuration for data owners, as we wanted the toolkit to be as simple as possible to use. The first element of the toolkit is a Python package that implements an experimental private data linkage algorithm. The algorithm uses trainable hash embeddings to compare and match datasets. Python users can download and use the package locally, without any cloud set-up. We encourage users to explore its features and compare performance on their own datasets or on publicly available evaluation datasets.
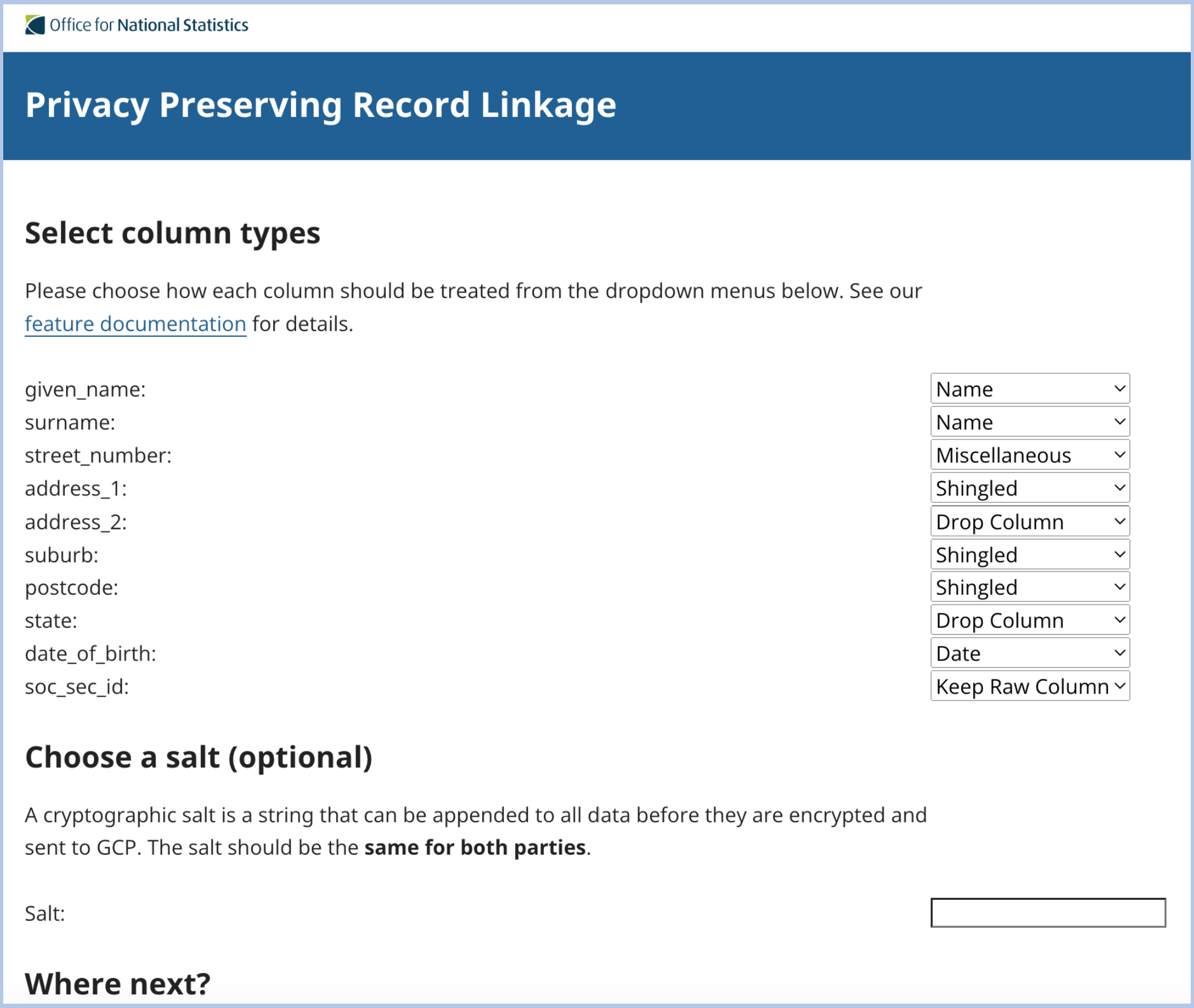
The second part provides an end-to-end demo of setting up and running a secure enclave server on Google cloud for private data linkage. The demo consists of shell scripts, a web app, and tutorials. The tutorial demonstrates how to set up a Confidential Space virtual machine, with a web front end for a simple user experience and shows step-by-step how two organisations could use the Python package in the cloud architecture to perform eyes-off linkage of their datasets without sharing sensitive personal information.
The toolkit is experimental, and as such is not suitable for production use. If you would be keen to explore deploying it in a production setting, please contact the Data Science Campus.
Figure 2: Web front end for prototype tool (PPRL)
Next steps
Although our toolkit is currently tested on small-to-medium sized datasets, we are confident that the embedding approach is inherently scalable – the technology behind many modern search algorithms can handle 100-million-row datasets and thousands of comparisons per second.
In future work we plan to incorporate vector search libraries, such as Meta’s faiss or Google’s ScaNN, to enable the method to scale efficiently to larger datasets. We also plan to train the hash embedding model against large corpuses of matched data owned by the ONS. We are currently in discussion with colleagues in the ONS to apply the techniques and methods in the toolkit to a real case study.
As this is an exploratory proof-of-concept, we expect users to discover bugs and vulnerabilities, and we welcome feedback on all aspects of the demo. Users are welcome to submit issues on GitHub, or submit pull requests. We also welcome anyone interested in putting these ideas to use, to contact us at the Data Science Campus. By open sourcing the project at an early stage of development we hope to benefit from the expertise and perspectives of the wider data science community to improve the tool.