Identifying different roles in the social care sector using online job advertisements

The stability of the workforce is a significant problem in the social care sector. Currently, there is not a universal definition of a “social care role”, limiting how data can be used in this sector. Identifying job types in data sources such as job adverts, will increase the scope to measure turnover of staffing in the future using non-traditional data sources.
A better understanding of the social care workforce is important for employers, policy makers and researchers. Identifying specific roles within the sector can help target areas which are most in need of support. This would also consequently improve the quality-of-care users receive.
In this guest blog post, former data science apprentice Evie Brown now working with the Social Care Analysis team at the Office for National Statistics (ONS) presents work on grouping online job adverts by social care role. This project was a significant part of her final year of the Level Six Data Science Apprenticeship.
The Level Six Data Science Apprenticeship combines teaching data science theory through a university programme with working with real world projects in a workplace. A mentor from the Data Science Campus was able to support the apprentice to complete this work. This included advice about defining the project’s research questions and implementation of each classification method.
The data for this project were from the Reed.co.uk Application Programming Interface (API) and specifically collected for this research purpose.
For more information about the apprenticeships supported by the Data Science Campus please refer to our apprenticeship pages.
Previous research
Previous research to categorise job adverts have included assigning three-digit Standard Occupation Classification (SOC 2010) code to job adverts (using Reeddata) using Term Frequency – Inverse Document Frequency (TF-IDF). Developed by the Bank of England, this method used string matching (using known job titles), cosine similarity and fuzzy matching to assign an appropriate SOC code (Turrell, Speinger, Djumalieva, Copple & Thurgood, 2018). This method had an accuracy of 91% when compared to job adverts labelled using an Office for National Statistics (ONS) proprietary algorithm.
Arthur (2021) also used Reed data to show how job roles can be identified from job adverts using different machine learning models. Supervised tree-based algorithms were trained using data labelled by identifying specific words in the job title of an advert. This method returned an accuracy of 92%.
The Data Science Campus has previously investigated how logistic regression models could be used to automate the labelling of job information fields in ONS surveys to SIC (Standard Industry Classification, 2007) and SOC (2020) codes. This model had an overall accuracy of 84% when used on a test sample of census data. (Thanasis, Wood, 2021).
This research aims to build on these papers to test the feasibility of identifying job roles in a specific sector or domain, social care, using a combination of a binary supervised classifier and a semi-supervised model.
Data collection
Job advertisement data were collected using the Reed Application Programming Interface (API). Reed is a recruitment agency used by employers to advertise jobs online. People can apply for jobs through Reed by searching for specific roles by job sector or title.
A sample of social care and non-social care jobs were collected using the API publicly available through Reed’s developer website. An initial sample of jobs was collected using the key term argument “social care”.
Text pre-processing
To clean the text fields in the data we:
- made the text lowercase
- removed HyperText Markup Language (HTML) web addresses
- removed punctuation
- removed stop words (using the Natural Language Toolkit (NLTK) library)
- lemmatised words
- acronyms were converted into full text (for example “rgn” was converted to “registered general nurse”)
- removed recruitment specific terminology (for example “immediate start”)
- removed location names using a pre-trained spaCy named entity recognition model (NER)
The sample of job adverts were quality checked. Prevalent non-social care jobs were removed by searching for specific non-social care key terms in the job title of each advert. After processing, duplicated job titles were removed from the data, leaving a final sample of 8,995 social care jobs.
A sample of non-social care job adverts was also collected. These jobs were available through the Reed API but were not present when using the key term “social care”. After processing (using the same steps described for social care jobs) and sampling (removing adverts at random to balance the two classes), the number of unique non-social care jobs in the sample was 8,995. Therefore, the total number of jobs in the data was 17,990.
A new variable was created by combining the cleaned job title and cleaned job description from each job advert into a single document called “jobTitleDescription”.
Both embedding and frequency matrix models were tested as word vector representations:
- term frequency-inverse document frequency (TF-IDF)
- FastText
- SentenceBert (all-MiniLM-L6-v2)
selection of parameters and inputs used in the TF-IDF model are:
- ngram_range: (1, 1)
- min_df: 1
- max_df: 1.0
- stopwords: none
- analyzer: word
- max_features: none
- binary: false
- norm: l2
Removing non-social care job adverts
The data were split into two samples: training (14,392 jobs; 80%) and testing (3,598 jobs; 20%). Twelve different supervised machine learning classifiers were trained on features created by implementing the following word embedding methods on the “jobTitleDescription” variable:
- logistic regression
- random forest (RF) classifier
- XGBoost classifier
- support-vector machine (SVM)
The models were used to predict a sector label for each job advert: “social care” (1) or “not social care” (0).
Results
After training and testing, four of the top five performing models (ranked on testing accuracy score) were trained on term frequency-inverse document frequency (TF-IDF) word embeddings. Conversely, four of the bottom five performing models were trained using FastText word embeddings.
Table 1: The training and testing outputs for the best four performing classifiers for the combined job title and job description, ranked by testing accuracy score.
| Model | Hyperparameters | Word Embedding | Accuracy Score | Precision | Recall | F1 | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | Train | Test | |||
| XGBoost | n_estimators = 100 max_depth = 3 learning_rate = 0.1 objective = binary:logistic booster = gbtree | TF-IDF | 1.0 | 0.96 | 1.0 | 0.95 | 1.0 | 0.97 | 1.0 | 0.96 |
| Support Vector Machine | C = 1 kernel = rbf degree = 3 gamma = scale coef0 = 0 max_iter = -1 | TF-IDF | 0.99 | 0.95 | 0.99 | 0.96 | 0.99 | 0.94 | 0.99 | 0.95 |
| Logistic Regression | C = 5.62 max_iter = 500 penalty = l2 solver = liblinear | TF-IDF | 0.98 | 0.95 | 0.98 | 0.96 | 0.98 | 0.94 | 0.98 | 0.95 |
| Random Forest | n_estimators = 40, min_samples_split = 2 min_samples_leaf = 1 max_features = sqrt max_depth = 30 bootstrap = False | TF-IDF | 1.0 | 0.93 | 1.0 | 0.95 | 1.0 | 0.92 | 1.0 | 0.93 |
The performance of each classifier was measured through confidence density plots and confusion matrices. Figure 1 shows the confidence density plots for the top four models shown in Table 1. These graphs plot the prediction probabilities for each “true positive” (social care) and “true negative” (not social care) job advert in the data.
Figure 1: Confidence density plot visualizing the prediction probabilities for true positive and true negative plots in the testing sample of job adverts for top four performing models
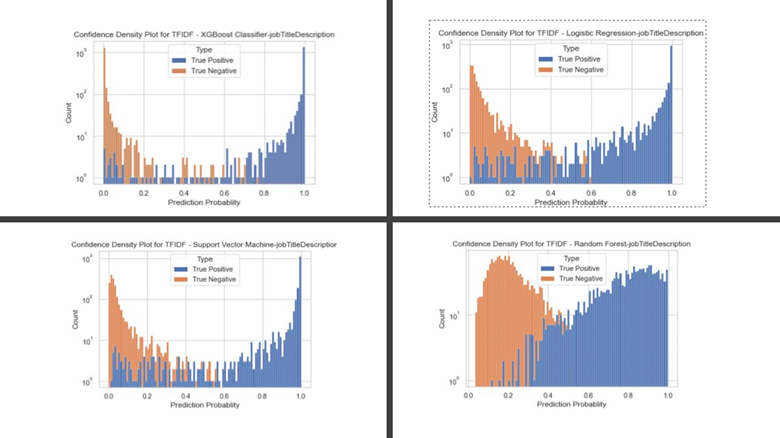
Similarly, the confusion matrices of the same models show most test data job adverts correctly classified into “social care” or “not social care” roles, as shown in Figure 2.
Figure 2: Confusion matrix showing the predictions of job adverts in the test sample by whether the predicted label is correct for top four performing models
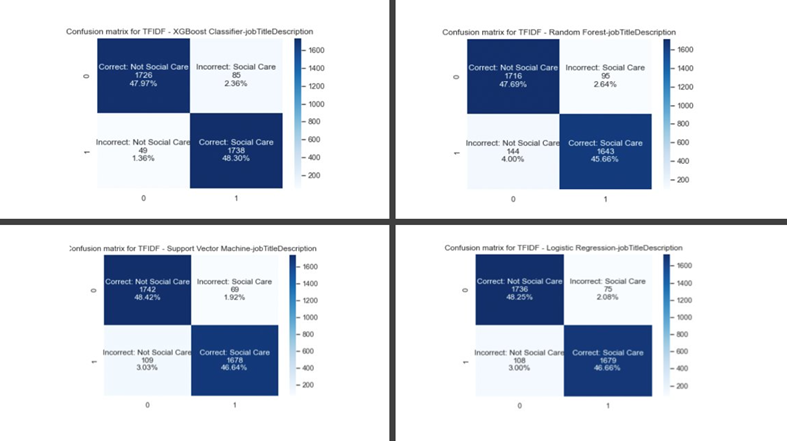
Considering each metric, an XGBoost classifier using TF-IDF word embeddings was selected as the best method in identifying adverts in the social care domain. This model was used to predict a “social care” and “nonsocial” label for each job advert collected. The job adverts predicted as “social care” were filtered from the sample (9,028 jobs).
Identifying job roles
The next stage used a semi-supervised model to identify specific job roles. First, job roles were assigned to a random sample of “social care” job adverts by string matching. The key terms and relevant job role label searched for in the cleaned job title of each advert were:
- Care assistant:
- care assistant, care home
- Social workers:
- social worker, support
- Community care
- community, domiciliary, dom care, domestic, housekeep, homecare, home
- Nursing
- registered nurse, nurse, medical, covid, vaccine
- Manager
- registered manager, manager, advisor, supervisor
An “Other” category was created by taking a random sample of job adverts predicted as “social care” but could not be grouped into a job role category using the key term search.
The categories were balanced using a random sampling method to reduce the size of the majority classes. Labelled job adverts, which were removed from the training set when sampled, were added to the “Not Labelled” category in the dataset.
Table 2: Number of job adverts in the training and testing sample for each individual class
| Sample | Class | Number of job adverts |
|---|---|---|
| Training | Care Assistant | 310 |
| Social Workers | 310 | |
| Community Care | 310 | |
| Nursing | 310 | |
| Manager | 310 | |
| Other | 310 | |
| Not Labelled | 6700 | |
| Testing | Care Assistant | 78 |
| Social Workers | 78 | |
| Community Care | 78 | |
| Nursing | 78 | |
| Manager | 78 | |
| Other | 78 |
A Scikit-Learn Label Propagation model was fitted on the training sample of data. A selection of parameters and inputs used in the Label Propagation model include:
- kernel: rbf
- gamma: 20
- n_neighbours: 7
- max_iter: 1000
The overall testing accuracy of the semi supervised classifier (a sample of manually labelled job adverts; 468 jobs) was 56.00%. Table 3 is a classification report showing the model’s performance for each job role. This report shows how certain classes, such as “Nursing” and “Care Assistant” are predicted better than other job roles such as “Social Worker”, “Community Care” and “Other”.
Table 3: Classification report of test sample job role prediction using semi-supervised Label Propagation model
| Job Role | Precision | Recall | F1-Score | Testing sample |
|---|---|---|---|---|
| Care Assistant | 0.65 | 0.79 | 0.72 | 78 |
| Social Worker | 0.46 | 0.59 | 0.52 | 78 |
| Community Care | 0.46 | 0.45 | 0.45 | 78 |
| Nursing | 0.76 | 0.78 | 0.77 | 78 |
| Manager | 0.53 | 0.49 | 0.51 | 78 |
| Other | 0.44 | 0.26 | 0.33 | 78 |
| Accuracy | 0.56 | 0.56 | 0.56 | 0.56 |
| Macro average | 0.55 | 0.56 | 0.55 | 468 |
| Weighted Average | 0.55 | 0.56 | 0.55 | 468 |
One reason for the poor performance of “Community Care” and “Social Worker” classes could be because of the similarity in the language used in these job adverts. For example, the type of work or location of job (at an individual’s home) may be similar. Furthermore, “Other” types of job adverts may be ambiguous and difficult to separate from the specified job role types.
Future improvements
Improvements could be made by training the initial classification model on more data to increase the variation of non-social care jobs. This would improve the accuracy of classifications on unseen text data from different sources.
Furthermore, introducing a “human-in-the-loop” step with manual validation of the specific social care jobs could improve the quality of initial sample used to train the semi-supervised model. This would correct adverts that have been erroneously mislabelled through string matching.
Also, testing the model on a “gold standard” sample would validate the actual accuracy of the classifier to predict job roles for specific social care job adverts labelled using expert domain knowledge.
Conclusion
In summary, a binary classifier and semi supervised model could be used to group different job roles from a specific domain. However, it is apparent that better labelled data, particularly when assigning job roles to different adverts, is needed to ensure consistent and accurate predictions across all job role types.
The outcome of this project includes the potential, and challenges, of using unstructured text data. This research is part of a wider programme of on-going work at the ONS to help enhance the evidence base of the adult social care workforce. The findings from this project will help identify which data sources can be used to fill evidence gaps in this sector in the future.