Using large language models (LLMs) to improve website search experience with StatsChat

Overview
We have been exploring how natural language processing (NLP) techniques and LLMs could be used in the future to improve website search experience for end-users. We developed “StatsChat” as an experimental search pipeline and front end web application to try and improve on the existing search engine capability of the Office for National Statistics (ONS) website. Today, we are releasing the code base for StatsChat as an open-source repository on GitHub.
We investigated if relevant text responses can be provided from search prompts using retrieved information from historical pages on the ONS website, though the same approach could be applied to any document store. We hope this work will inform and support collaboration with others who are looking at similar approaches to improve information retrieval, whether from websites or other document stores.
StatsChat general approach
Many websites have search engines that use algorithms based on how often individual keywords appear on a page. This may not reflect what the user meant to search for, or the information contained on the pages. Additionally, even if a user is taken to the correct page on a website, they may still struggle to find the right piece of information within that page.
Our approach with StatsChat uses embedding search to interpret the semantic meaning of queries and documents together with an LLM. This returns to the user relevant sentences from shortlisted documents. For transparency reasons, the models used, their sources and limitations are openly available. The approach also ensures that data are only stored on the ONS infrastructure. This avoids relying on proprietary models and provides assurance of user data security.
It’s worth mentioning that the generative step of StatsChat is only being used in a very limited context: to find and retrieve the right parts of an ONS bulletin for the user. This is essential to ensure the system does not generate incorrect or biased information.
Technical solution
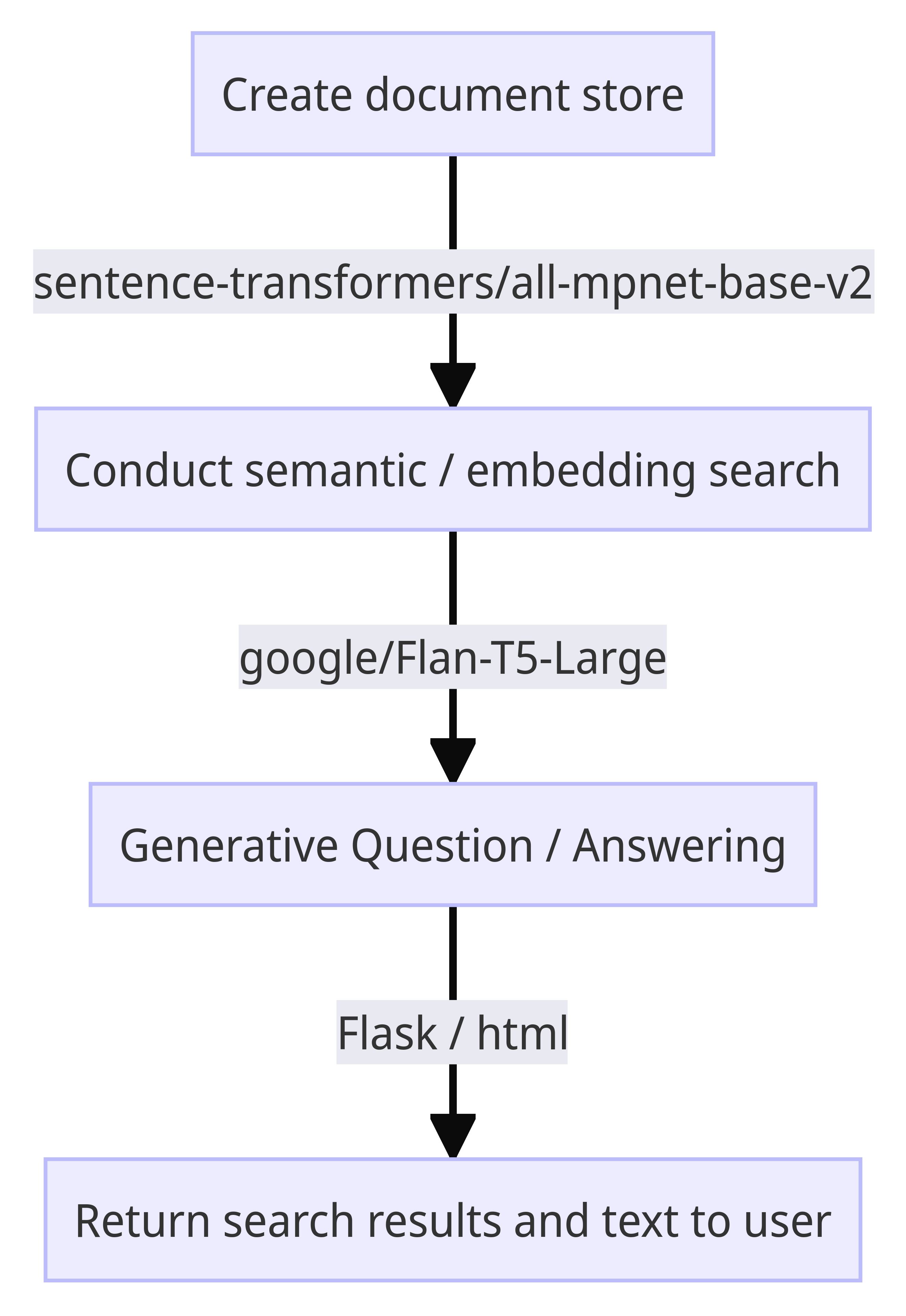
Figure 1 shows a flow chart detailing our technical solution and an overview of our approach. We obtained and stored a historical archive of every publication on the ONS website, published since 2016, with accompanying metadata. Items in the document store were then partitioned into chunks of roughly 1000 characters and converted into vector embeddings using a sentence transformers model. This allowed us to run an embedding search algorithm to collect the most relevant web pages from the user query.
Next, we conducted generative question-answering (GQA) using the open-source Flan-T5-Large model from Google. The shortlisted documents and the user question were both fed into the model, and it was prompted to answer the user’s question only using paraphrased sentences from the shortlisted documents.
The application was served using Flask, with a simple HTML front end and rest API endpoint. The search results page currently provides a single free-text answer generated from the generative question answering step, as well as the full results from the embedding search stage, linked to metadata. This allows the user to gain easy access to the text on the relevant section on the webpage.
Figure 1: Flow chart of technical solution
Results and performance
The embedding search shows a clear improvement upon the current website performance in terms of picking out relevant sections of webpages from the user query. We have found it particularly effective at retrieving information for very specific queries.
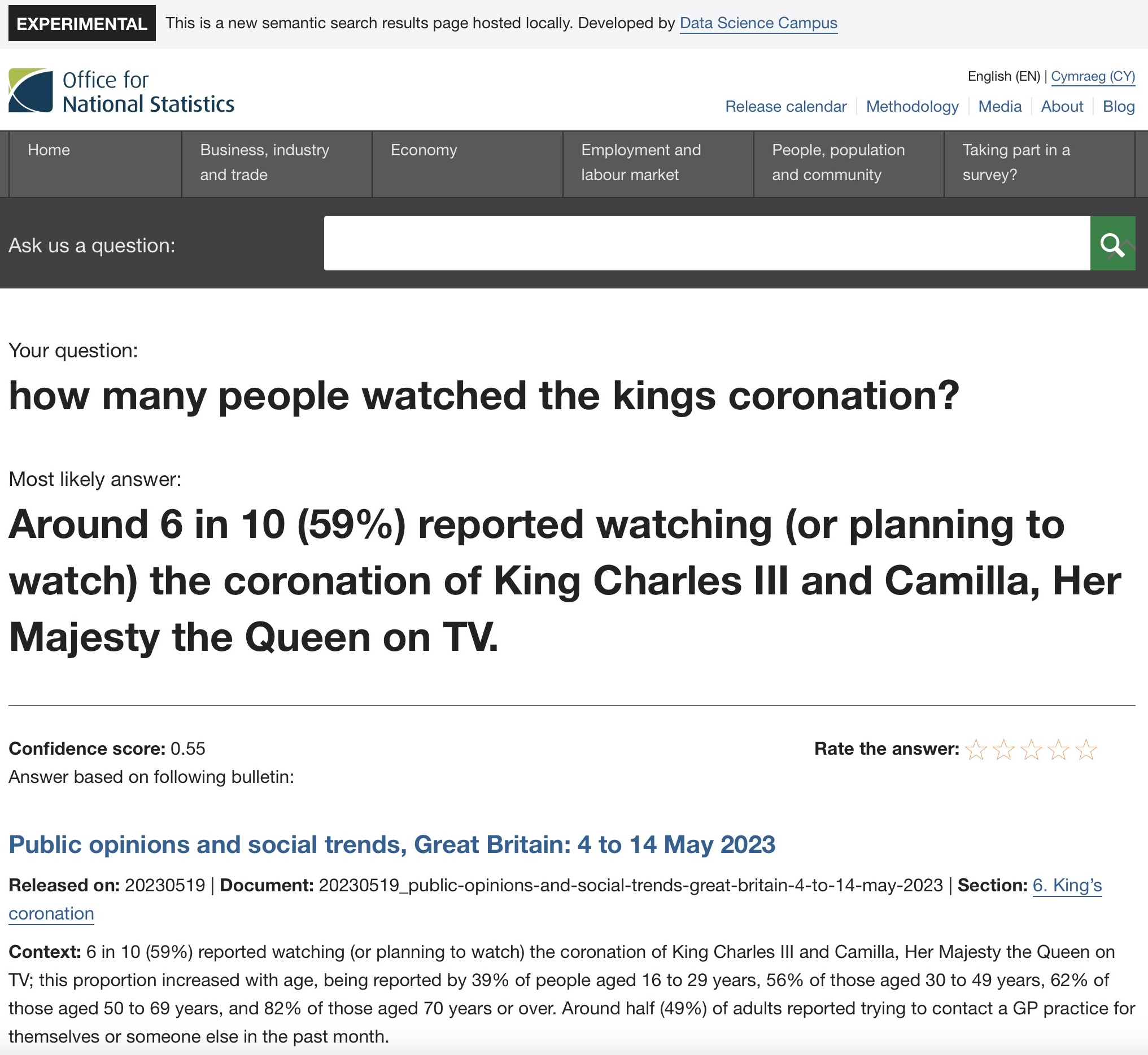
For example, Figure 2 shows results from a user request asking about the proportion of people that watched His Majesty King Charles III’s coronation. This specific statistic has only been published once in one of our regular public opinions and social trends bulletins. In this example, StatsChat was more effective at identifying the bulletin relevant to the query and the right section within that bulletin. In contrast, we found that the search tool was less effective at returning succinct and accurate answers to very broad questions, for example, “are we in recession?”.
We are aiming to improve the performance of the tool over time, by introducing fine-tuning into the GQA model following internal testing. This will include being able to better link public queries to technical terms used by a national statistics institute.
Figure 2: Search results from the prototype search tool (StatsChat)
Risks and limitations
It is important to emphasise that the development of StatsChat is currently in early experimental stages. The code is being made publicly available solely for research purposes. We are actively working to ensure the tool meets rigorous tests of data security and ethics.
Most notably, although we have made efforts to eliminate hallucinations in the GQA stage, we have not yet conducted enough testing and refinement to ensure this is always true for all search queries. We also intend to strengthen the resilience of the system to prompt injection attacks, ensuring there is no risk of the tool being used to generate misinformation. Finally, we intend to do further research and testing on the presence of bias in the models we have currently selected.
Code repository
The code repository is currently structured to be run in parts. A standalone pre-processing script covers the task of converting pages on the ONS website to embedding vectors. The front end Flask app is run from a single script, while the retrieval and GQA pipeline is its own module. Various parameters, including the choice of models, approach to converting documents into vector embeddings and the prompt for conducting GQA can be found in the configuration files.
We have included a small test dataset of publicly available bulletins from the ONS website to demonstrate how documents could be stored and accessed by the search tool. It is conceptually possible for the tool to be used on a range of documents, but this would need some reconfiguration. Further information on compiling and running the code base can be found in the README file on the Github repo.
Next steps
We are currently conducting further testing and refinement of StatsChat. This includes fine-tuning and dealing with the risks and limitations listed in this blog post. We are also implementing a feedback system where users can rate their answer.
The first step is for us to ensure StatsChat meets the highest standards of data ethics and data security tests. Depending on the outcome of testing, we may look to gradually make this tool more widely available to users and will continue to inform on our progress with this project.
If you are interested in this work or would like to collaborate with us on a similar project, get in touch with us via email. For regular updates on our work, follow us on Twitter and sign up to our newsletter.