ScannerAI – Advancing Receipt Data Processing with AI

Introduction
The Data Science Campus (DSC) are actively developing a tool, which aims to significantly improve the efficiency of processing household spending information in the Office for National Statistics (ONS). In a first for the organisation, we have been exploring how multimodal generative AI can automatically extract data needed from images of receipts sent to us by the public as part of the Living Costs and Food (LCF) survey. By combining this with automated text classification, we aim to streamline the processing of tens of thousands of receipts submitted by respondents each year.
As the receipt information is a key source of data for economic statistics including household spending and income, we expect this to result in improvements to the quality and timeliness of some of our core economic statistics. We have released the code base as a public repository on GitHub, to support others in exploring practical applications of multi-modal generative AI, while we further explore the steps needed to use it in operations.
Background
The ONS gathers household receipts as part of the LCF survey and these receipts provide detailed insights into respondents’ purchases, feeding into economic statistics including the national accounts. Traditionally, handling these receipts involves two major stages: extracting each product and price from receipt images and classifying each product to a standard statistical classification, both of which demand significant manual effort. To highlight the extensive volume of data, 3,993 households completed both interview and diary sections of the LCF survey in Great Britain in the financial year ending (FYE) 2023 (April 2022 to March 2023), yielding up to 60,000 receipts.
The emergence of generative AI, including multi-modal models that can process both image and text, offers a valuable opportunity to streamline this process. Over recent months, we have explored various technologies, including image processing, Optical Character Recognition (OCR), Large Language Models (LLMs), Natural Language Processing (NLP) and classification techniques. These methods have shown promising results in both extracting the information needed from receipts, such as shop names, item descriptions and prices among other fields, and classifying these records to the COICOP (Classification of Individual Consumption by Purpose).
The pipeline we have developed, which is still in development, is intended to be used by our social surveys operational team to spend less time and resource on manual data entry and focus on higher value task such as quality assurance. Lowering the operational cost could unlock our ability to raise sample sizes which has been a key recommendation from the Office for Statistics Regulation (OSR) in recent years. In addition, it may reduce the timeframe to process LCF data, which would bring expenditure information into GDP sooner, allowing for greater reconciliation of data sources.
Data Processing Pipeline
In the LCF survey process, receipts can be collected via three ways:
- paper receipt collected by interviewers and scanned via a mobile app
- image sent via text to an interviewer’s work phone
- image sent by email to the interviewer
Once the receipts are in digital form, our data processing pipeline involves several key steps (see Figure 1):
Pre-processing: techniques like noise reduction, contrast enhancement, skew correction and cropping are applied to optimise image quality.
Optical Character Recognition (OCR): For the pre-processed images, we tested a range of OCR tools including Tesseract, Google Vision, and the Gemini Pro multimodal LLM, to extract the required text from images. Our current preference based on early testing of accuracy is to use Gemini Pro for this step.
Text parsing: The extracted raw text is then restructured into the format needed for a table using an LLM (also Gemini Pro). We are exploring whether we can combine the OCR and text parsing steps given both stages may use the same LLM.
Product classification: We assign receipted items to a COICOP code using an automated classification process. We are currently testing two different approaches: a traditional machine learning classification algorithm (such as Random Forest) as well as our recently developed ClassifAI microservice, which also utilises Generative AI.
Figure 1. Data processing pipeline of receipt images
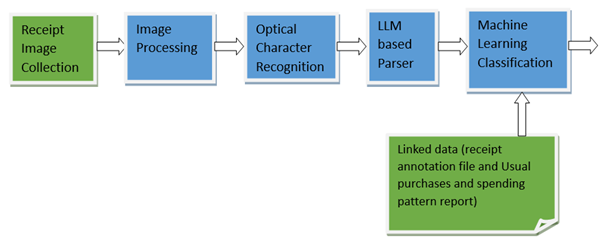
We are exploring how we might be able to improve on the classification accuracy, by linking receipt data with additional datasets such as receipt annotations and spending reports from the respondent’s interview. This approach ensures a more holistic understanding of the purchase context.
The final output from the pipeline is table that can be viewed, edited, and approved by ONS colleagues involved in the data processing stage. The table includes information on the shop name, individual items with their prices, COICOP codes for each item, payment method and total amount. By integrating these technologies, we are enabling a more efficient and effective workflow, reducing the need for manual data entry, and improving the speed and accuracy at which we can process the data.
Developing a Prototype
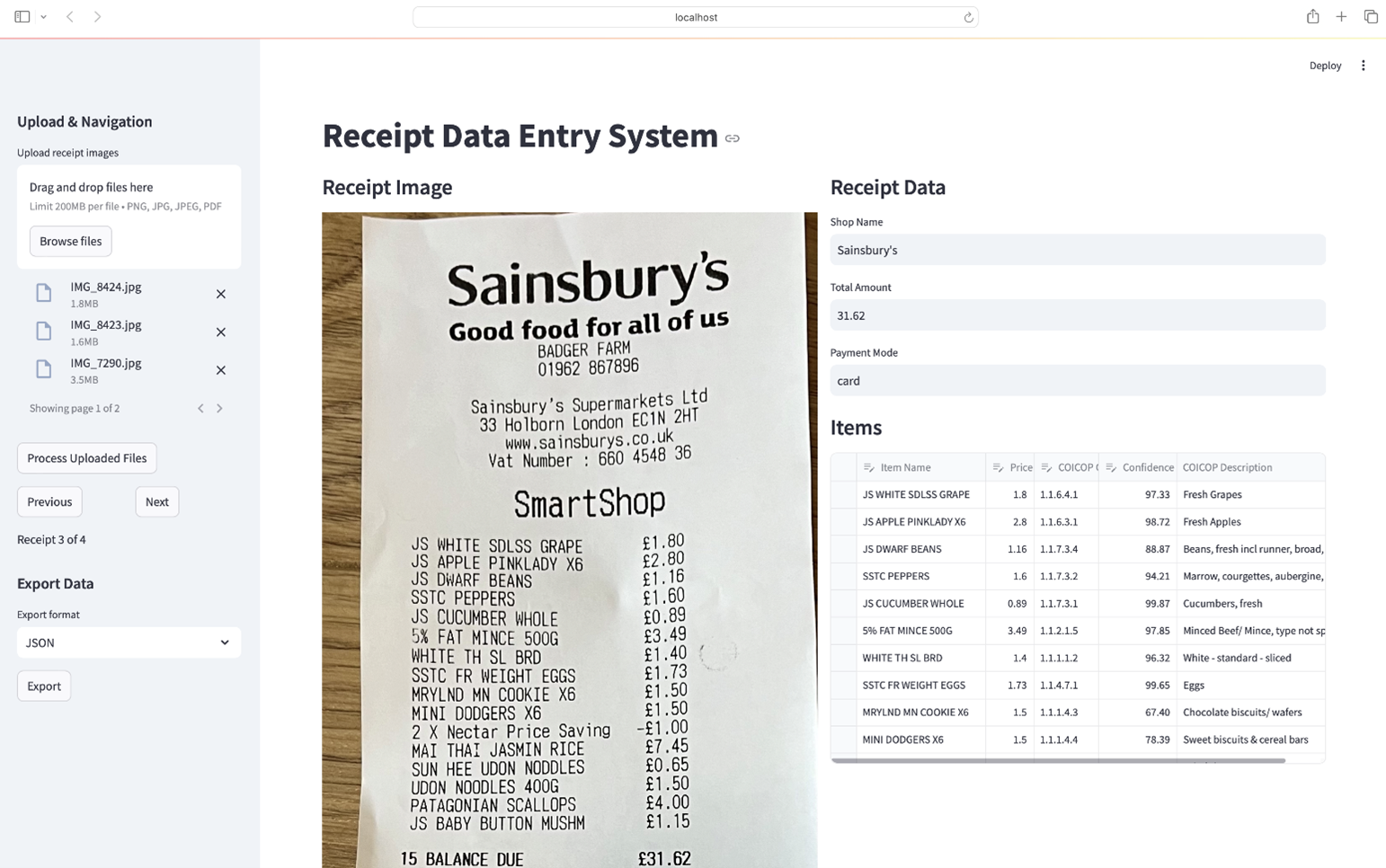
Our prototype runs the data pipeline outlined above and manages outputs through a user-friendly web interface. Figure 2 shows the mock interface, where the left panel can be used to upload and navigate receipt images, the middle area shows the selected receipt, and the right panel shows the extracted information including shop name, total amount, payment mode, a list of item descriptions, prices, COICOP code confidence score and COICOP description. We envisage that users of the tool will benefit by switching from entirely manual data entry, to focusing on mainly quality assuring the outputs of the pipeline and, if needed, amending the extracted information via the add, edit, and delete functionality.
Figure 2. Screenshot of the mock interface
Next Steps: Continuous Testing and Iteration
While we are excited about our progress so far, we are in an early phase of the work and are likely to make many significant changes to both the pipeline and user interface. The next steps will focus on evaluating the current accuracy of the processing pipeline using test receipts that have already been processed and classified by humans. This will allow us to monitor and refine the approach and iterate with teams to ensure the solution adds value.
The code for our prototype tool, developed to support the automated processing and classification of receipt images in the Living Costs and Food (LCF) survey, is available in a dedicated repository. The code can be accessed on Github. This repository includes all necessary components for setting up the data extraction and classification pipeline, allowing for reproduction and customization within compatible systems.
We invite feedback and suggestions from our stakeholders to enhance this ongoing project. Please contact us at datacampus@ons.gov.uk.