ParliAI – using AI tools to monitor parliamentary coverage of the ONS across the UK

Introduction
As part of understanding user need, monitoring parliamentary coverage is an important way to understand how people use Office for National Statistics (ONS) statistics, and how they would like them to be improved. We do the same for media content and across academia. This work is largely done manually or procured through third-parties. However, modern AI tools such as Large Language Models (LLMs) provide an opportunity to improve the quality and efficiency of this process.
The Data Science Campus (DSC) has worked to support our colleagues in the Parliamentary team by automating the process of capturing and reporting coverage of the ONS in political debates and written communications across the UK’s parliamentary chambers. For example:
Figure 1 – A report extract containing a contribution referencing the ONS in a House of Commons debate.

Today, we are publishing the code base for a tool we have developed (known internally as ParliAI) to automatically collate references to the operation and outputs of the ONS in parliamentary debate, and circulate internally in a tidy format. We have open-sourced our code to facilitate others applying this approach to their organisations, people or themes.
We hope this work will inform and support collaboration with others who are looking at similar approaches and welcome feedback on our approach, we would be very interested to hear from others – both developers and non-developers – about broader uses and evolution of the tool.
This is our latest output on using AI tool, building on recent publications on using LLMs to improve information retrieval (Statschat) and data classification (ClassifAI). As we explore use cases across ONS process (for example the Generic Statistical Business Process Model), from data collection to dissemination, we aim to foster collaboration and improve understanding of the utility of these new AI tools by working in the open.
Intended use in the ONS
Daily reports are sent to registered users in the ONS with a compendium of weekly coverage also available to an ever-expanding list of users from across the civil service. This tool captures explicit and implicit references to the ONS, allowing for analysis of how the organisation’s outputs are used and reflect the needs of the population. Contributions from all elected politicians – made in any of the country’s parliamentary chambers – are recorded. An abridged example of a daily report can be found below:
Figure 2 – abridged example of a daily report

It is noteworthy that hyperlinks are rendered automatically in the report, allowing the reader to access further information on both the contributor and the wider debate or written communication. It also makes the content more accessible for readers to verify its provenance.
Technical approach
In order to build our daily reporting tool, we have used the theyworkforyou website provided by mySociety (a registered charity in England and Wales). The site shares transcripts of parliamentary debate and official written communications across all UK chambers:
- House of Commons
- House of Lords
- Westminster Hall
- Scottish Parliament
- Welsh Parliament / Senedd
- Northern Ireland Assembly
Figure 3 – daily workflow (technical)
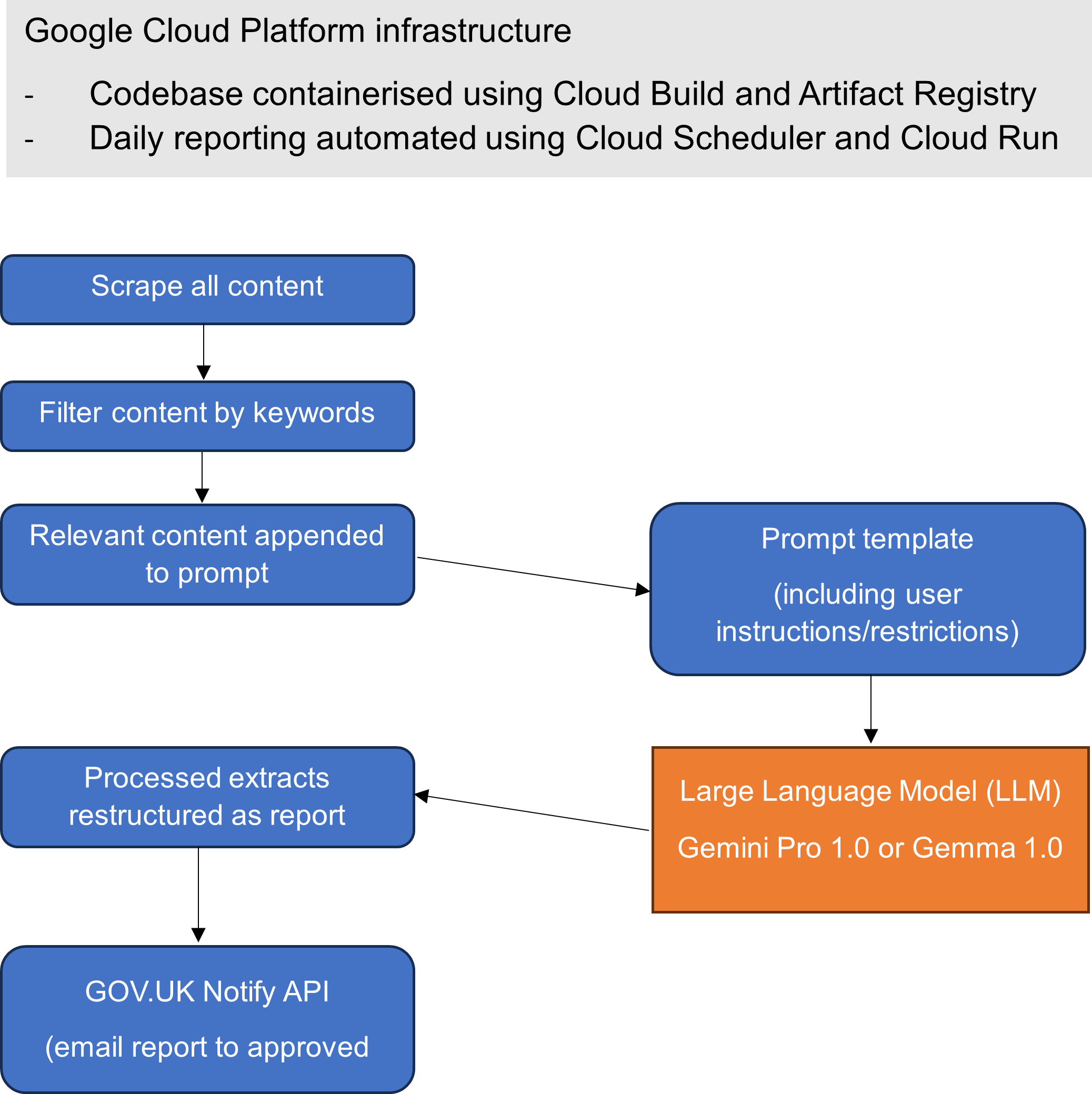
First of all, content is scraped daily from the theyworkforyou site. We filter all daily content with string-matching, using the key terms “ONS” and “Office for National Statistics” only. All contributions – containing one or both these terms at least once – are chunked and stored in JSON format. Contributions that are larger than 20,000 tokens (typically long speeches) are divided into chunks of no more than 20,000 tokens. A 4,000 token overlap is applied so that context before and after a chunk is available to the LLM. This ensures the best possible coverage of explicit and implicit mentions of the organisation.
A prompt (further discussed below) is passed – along with this parliamentary content – to be processed by the LLM, one call per chunk. In this final step, the LLM isolates the specific mention (or mentions) of the organisation and expands its view before and after each. It returns a word-for-word block of sentences from the original content. The final report is a construct of each of these LLM responses within a prescribed template.
As with all LLMs, the prompt strategy is critical to communicating with the model programmatically. Initially, we chose a few-shot prompt technique, providing example inputs and outputs to the LLM to encourage it to conform. However, we rejected this technique in production given the versatility of our chosen models: Gemini Pro 1.0 and Gemma 1.0 (both accessed via the GCP Vertex AI Model Garden). Prompting is notoriously subjective but we have provided an example below:
Figure 4 – an illustrative example of a prompt template sent to the LLM

Given the obvious sensitivities around misattribution or embellishment, we have implemented three strategies to mitigate this. First, an initial string-matching step requires that the wholes chunk (generally a single contribution from a politician) is passed to the LLM if it contains any of the keywords, ensuring that the full context of what has been said or written is available. Second, a prompt template presents clear constraints to the LLM, such as “extract ONLY sentences verbatim” and “Do not paraphrase”. Finally, a post-processing check is currently being developed to verify that the LLM output is present word-for-word in the original text.
Once the report has been finalised, we use the GOV.UK Notify API (built by the Government Digital Service) to send e-mails. Note: this service is available for use by anyone working in central government, a local authority or the NHS.
Evaluating success
Internal stakeholders have reported that the ParliAI tool performs well compared with the previous approach. Over a two-week period in April 2024, the tool was evaluated by these users:
Precision
100% of written parliamentary questions and oral contributions were relevant to stakeholders compared with just 7% and 13% respectively for the previous approach.
Recall
A side-by-side comparison of ParliAI with the previous approach during the same period showed that just one question and one contribution (both captured using the previous method) were missed by ParliAI. However, three questions and seven contributions (collected by ParliAI) were missed by the previous approach.
Evidently, the acceptable use of such a tool is paramount. Recipients of the daily reports are reminded that individuals must exercise caution, understanding for themselves what has been said and by whom. Report content is not directly quoted for any onward briefing – internal or external – and links to the original content are always provided within the report so that users can easily check for themselves and better understand the context of what has been reported. This is not a project about creating content rather it is intended to promote visibility of political discourse, making it more accessible and harnessing it to help improve our organisation’s outputs.
One key question in this project has been “why use an LLM at all?”. It is true that string matching can be achieved simply in Python (and other coding languages), retaining only sentences containing the key words. However, the LLM has proven to be hugely flexible in retaining context around these sentences, securing the flow and semantic completeness of the contribution. In speech, there are often references to themes before and/or after they are explicitly mentioned. An example of this is highlighted in one debate below:
Figure 5 – example output from LLM illustrating implicit coverage (implicit coverage highlighted)

Value and wider applications
While this project focused on a very specific brief – delivering insights internally for the ONS – very simple changes could realise very significant benefits more widely:
- By updating key words and phrases, reports could be automated for any organisation.
- By scraping different content, the coverage of an organisation in a different context could be realised. An obvious example might be news feeds although caution must be exercised to ensure that this is permissible on a case-by-case basis.
A public code repository is provided to illustrate our workflow and to encourage onward development. We would very much like to hear ideas for both future development and collaboration. Please contact datasciencecampus@ons.gov.uk for more information on this project or any of our other projects.